
このコラムは、株式会社エル・ティー・エスのLTSコラムとして2021年3月に掲載されたものを移設したものです。
ライター

大手小売業におけるRPA導入や、製造業の経営管理業務可視化・標準化を支援。現在は大手製造業のデータマネジメント構想策定支援に携わり、全社横断的なデータ活用に向けた取り組みを行っている。(2021年6月時点)
本コラムでは「製造業におけるデータマネジメントの第一歩」と題し、第1回では「データマネジメントの考え方とデータが使えるための条件」について、第2回では「データマネジメント活動の方法論」について、第3回では「データマネジメント活動の方法論を動かす仕組み」についてご紹介します。
1. 企業におけるデータ活用の現状
企業におけるデータ活用の現状を、とあるメーカーのクレーム対応を例に見ていきましょう。このメーカーの品質管理課では、クレーム対応のためラインのデータをかき集めて分析を行い、原因を追及しようとしています。そこでまずラインのリーダーやIT担当者に問い合わせ、半日後にデータを入手しました。しかし、集めたデータはタイムリーに更新されていないものもあり、クレームのロットが処理されるよりもずいぶん前のデータもあるようです。また、データを分析したい単位に変換したいのですが、品種を表すコードがラインごとに異なる単位で入力されている状態で、各データが何をあらわしているのかわかりません。再度現場に問い合わせるも、「管理しているのは自分ではないのでわからない」と言われてしまい、データの分析に着手するまでずいぶん時間がかかってしまいました。
このように、データを分析するための準備に多くの時間がかかってしまっている状態は「データ活用ができている」とはとても言い難いですよね。企業IT動向調査2020によりますと、データ活用に取り組んでいる企業は8割にのぼります。しかし、複数の部署やラインをまたいだ組織横断的なデータ活用ができる環境を構築している企業はわずか2割に留まっており、組織横断的にデータを活用することの難しさがわかります。

出典:企業IT動向調査2020(日本情報システム・ユーザー協会, 2019年度調査、https://juas.or.jp/cms/media/2020/09/JUAS_IT2020_original_Ver.2.pdf)
一体なぜ、多くの企業でデータ活用が進まないのでしょうか。まず、近年急激にデータの種類・量が増加したことが大きな要因になっていると考えられます。これによりデータ管理工数やコストが増加したため、データを活用できる状態で維持することが困難になってきています。結果、データが“使えない状態”となり多くの企業でデータ活用が進まなくなってしまっているのです。つまり、データ活用を進めるためには「効率的にデータを管理できる状態」と「データが“使える状態”であること」が必要となります。この2つを実現する活動を『データマネジメント活動』といいます。クレーム分析の事例では効率的にデータを管理できておらず、データが“使える状態”ではなかったのです。どういうことか、データマネジメント活動の効果とあわせて詳しく見てみましょう。

2. データマネジメントの4つの活動と効果
データマネジメント活動には主に4つ活動があります。それぞれの活動と、それによって期待される効果を見てみましょう。
①データの見える化
データが発生してから削除されるまでの流れをデータライフサイクルといいます。データマネジメント活動では、あるデータのライフサイクルにおいて、誰が、いつ、どこで、どのように関わっているのかを明らかにします。このようにデータを見える化することによって、データ活用者は必要としているデータがどこにあるのか把握できるようになります(データが“使える状態”)。
クレーム分析の事例では、誰がデータを持っているのかわからずラインのリーダーやIT担当者に問い合わせており、データが“使えない状態”でした。データを見える化することによって、問い合わせる必要がなくなり、問い合わせを受ける人、主に現場の対応負担も軽減されることが期待できます(効率的なデータ管理)。
②無駄を省く
データの見える化によって、無駄なデータを見つけることができます。無駄なデータとは、複数のシステムに重複して入力されているようなデータを指します。
例えば、トラブルで設備が停止した場合、生産技術部門は設備情報を管理しているシステムに停止情報を入力し、一方で、製造部門は配台計画を管理しているシステムに停止情報を入力するという管理をします。いわゆる二重入力です。そしてその後、設備が再稼働した時には2つのシステムに入力されたデータを各部門の担当者が修正する必要があるため、今度は修正の手間が二重で発生してしまいます。このような重複したデータ管理を行っている企業は多いのではないでしょうか。
データが誰によってどのシステムに登録されているか見える化がされていると、このようなデータの二重入力・二重管理を見つけることができます(効率的なデータ管理)。
③活用度合いを上げる
わざわざ現場が伝票にメモを記録しているのに誰も見ていない、せっかくセンサーを取り付けたのに取得データが特定の用途にしか使われていないというようなデータはないでしょうか。データを企業の資産として捉え価値を向上させるためには、データを複数の用途で使うことが重要となります。データマネジメント活動によってデータを使える状態にすると、データを活用しやすくなり、活用用途・活用機会が増えることが期待できます。その結果、ものづくりのQCD向上や、その結果としての経済的メリットを受けることができるでしょう。また、データの活用度合いが向上することにより、使われないデータの管理コストも削減することができます(効率的なデータ管理)。
④データ品質を上げる
「データが使える状態」とは、データ入力者の提供するデータの品質が、データ活用者が欲しいデータの品質を上回る(もしくは同等である)状態を指します。データマネジメント活動では、データ活用者が欲しいデータの品質要件を調査し、データ入力者の提供するデータ品質がその要件を満たすような仕組みづくりを行います。
また、現状のデータ品質を評価して改善につなげる体制をつくることで、データを高品質な状態で維持することができます。これによって、データ活用者がデータ収集・加工にかかる工数を削減したり、データの活用度合いを上げたりすることができます。クレーム分析の事例では、データが最新化された状態で維持されることによって、ラインごとに異なる品種の単位から分析したい単位に変換する工数を削減したり、取得したデータから精度の高い分析結果を得ることができたりします(データが“使える状態”)。
このようにデータマネジメント活動は企業にとって重要な活動であり効果が期待されますが、実施段階で困っている企業が多いのが現状です。特に製造業では対象となるデータの種類・量が多く、どのようなデータが社内に存在するか把握するのにも一苦労です。また、拠点・部門・ライン・工程ごとにデータの状態や管理方法がバラバラになってしまっています。では、色々な立場の人がそれぞれデータ活用をするためには、データがどのような条件を満たす必要があるのでしょうか。
3. データが使える条件とは?
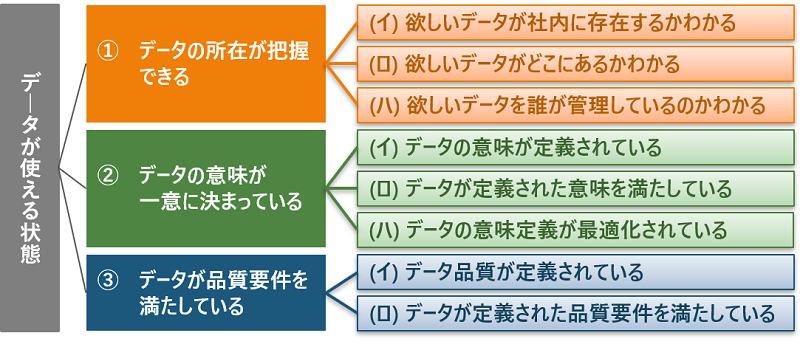
データを“活用できる状態”で維持するためには、①データの所在が把握できる、②データの意味が一意に決まっている、③データが品質要件を満たしている、この3つの条件を満たす必要があると考えています。
①データの所在が把握できる
データ活用者が分析のためにデータを収集するとき、データがどこにあるか、誰に聞けばよいかわからないとデータを集めるのに時間がかかってしまいます。
このような課題を解決するためには、データが次の条件(イ・ロ・ハ)を満たす状態で管理する必要があります。
(イ) 欲しいデータが社内に存在するかわかる
クレーム分析の事例では、実績データは社内に存在することが明らかでしたが、社内に存在すると思っていたデータが実は取得されていなかった、ということもあります。データの種類が増えていく今後、どのデータが存在するのか、誰でもわかるように管理することが求められます。
(ロ) 欲しいデータがどこにあるかわかる
もし工程のローカルフォルダで管理されているようなデータでも、存在する部署やシステムが見える化されていれば、色々な人に問い合わせるなどの手間をかけずにデータを入手することができます。
(ハ) 欲しいデータを誰が管理しているのかわかる
クレーム分析の事例では、取得したデータの意味を現場に問い合わせるも「管理しているのは自分ではないのでわからない」と言われてしまいました。データの管理者が明確であれば、データに関する不明点を誰に聞けばいいのかわかったはずです。
これらの条件(イ・ロ・ハ)をデータが満たすことによって、データ活用者がデータを収集することができます。
②データの意味が一意に決まっている
条件①「データの所在が把握できる」が満たされ活用者がデータを集めることができたとしても、入手したデータの意味がわからないとデータを活用することができません。データの項目名とデータの中身(コード)が一致していないケースは製造業で多く見られます。例えば、製品を表すコードに製造の加工条件や材料の新旧といった意味を持たせすぎてしまい、当初定義した項目名とは異なる意味のコードが存在してしまうケースです。
このような課題を解決するためには、データが次の条件(イ・ロ・ハ)を満たす状態で管理する必要があります。
(イ) データの意味が定義されている
データの意味を定義することは、データの観点を決めることです。あらかじめデータの観点が決められていないと、部署や人によって見たい観点でデータを登録してしまいます。その結果、1つのデータ項目に、同じ製品を表す様々なコードが存在してしまいます。これではデータの意味が一意ではなく、活用することができません。業務で多くの観点が必要とされる製造業では、特にデータの観点を決めることが重要です。
(ロ) データが定義された意味を満たしている
データの意味を定義するだけではなく、意味を満たすようにデータを入力しなければなりません。そのために、データの入力ルールを定めて、データ入力者に守ってもらうことが必要です。
(ハ) データの意味定義が最適化されている
意味が定義され、その通りに入力されていたとしても、データ活用者にとって使いにくいデータだと活用するための変換に手間がかかってしまいます。次の条件③にもつながりますが、データ活用者が何のためにデータを使うのかを把握し、最適な意味定義をする必要があります。
これらの条件(イ・ロ・ハ)をデータが満たすことによって、データ活用者は入手したデータの意味を理解することができます。
③データが品質要件を満たしている
条件①と条件②が満たされ活用者が集めたデータの意味を理解できたとしても、データの品質が悪いとそもそもデータが使えなかったり、データを使える状態にするための加工に手間がかかったりしてしまいます。クレーム分析の事例では、タイムリーに更新されていないデータやクレームのロットが処理されるよりもずいぶん前のデータが含まれているなど、データがすぐに使えない状態でした。また、ラインごとに異なる品種の単位を分析したい単位に変換する手間も発生していました。このように、データ活用者が使いたいデータの粒度(数えられるものの括り方)と、現場で入力されたデータの粒度が異なるケースは製造業で多く見られます。
製造業でものをつくる工程では様々な粒度の品番が存在しています。製造課が工程で製造計画を立てるときの品番と、生産管理課が製品の品質を管理するときの品番は粒度が異なりますよね。このとき製造課と生産管理課の情報をつなげて分析しようとすると、データ活用者は品番の粒度を変換するのに時間と手間がかかってしまいます。
このような課題を解決するためには、データが次の条件(イ・ロ)を満たす状態で管理する必要があります。
(イ) データ品質が定義されている
データ活用者が何のためにデータを使うのかを把握し、データに対する要件を定める必要があります。データに対する要件の例として、日次で最新化されること、有効数字5桁を満たすことなどが挙げられます。
(ロ) データが定義された品質要件を満たしている
条件②(ロ)と同様に、条件(イ)で要件を定義しても実際に入力されるデータが要件を満たしていないと意味がありません。データ入力者が要件を満たすデータを入力するように、入力ルールを定める必要があります。
これらの条件(イ・ロ)をデータが満たすことによって、データ活用者は入手したデータを使って目的を達成する、つまりデータ分析を行うことができます。
ここまで説明してきた条件①~③をデータが満たすことによってクレーム分析の事例で発生していた課題が解決され「データが活用できている」状態になるのです。
ここまでの説明で、データマネジメントの必要性・効果と、データが使える条件がわかりました。ですが、これで明日からデータマネジメント活動が実施できる…と言える人はほとんどいないと思います。確かにデータのあるべき状態はわかりましたが、どのように実現すればいいのかわからず困ってしまいますよね。では一体、データが使える条件を満たすためには具体的にどのような活動をすればよいのでしょうか。必要な活動要素の一つとして、データの見える化を実現するためのデータの地図(データMAP)がありますので、次回コラムにてご紹介します。


